CLIP (Contrastive Language–Image Pre-training)
 CLIP Architecture
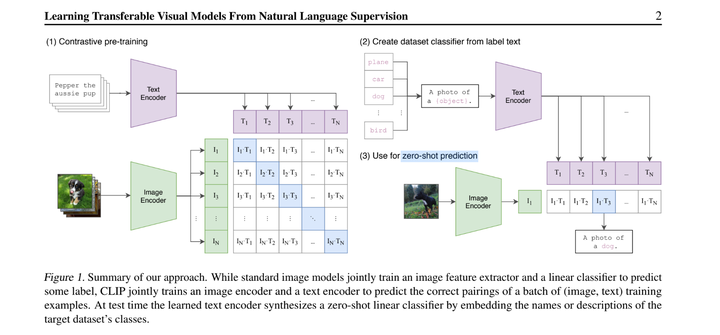
CLIP ArchitectureThe paper introduces CLIP (Contrastive Language–Image Pre-training), an approach to learn visual models that are highly versatile and adaptable to a wide range of visual tasks without the need for task-specific training data. Unlike traditional computer vision systems that rely on a fixed set of object categories they are trained to recognize, CLIP learns from a much broader range of data by directly learning from raw text paired with images. This method demonstrates the ability to understand and classify images based on natural language descriptions, enabling it to perform well across over 30 different computer vision tasks in a zero-shot or few-shot manner, often matching or exceeding the performance of task-specific supervised models.

Key aspects of CLIP
- Contrastive Pre-training: CLIP is trained on a large dataset of 400 million image-text pairs collected from the internet. The model learns by predicting the correct pairing of a batch of images and text captions, effectively learning a wide array of visual concepts directly from natural language descriptions.
- Zero-Shot Transfer: After pre-training, CLIP can perform zero-shot classification tasks by using natural language to reference learned visual concepts or describe new ones. This capability is tested across various existing computer vision datasets, demonstrating competitive performance even without using dataset-specific training examples.
- Scalability and Efficiency: The paper investigates the scalability of CLIP by training models of various sizes, showing that performance improves predictably with increased compute, highlighting the efficiency and effectiveness of learning from natural language supervision.
- Robustness and Generalization: Preliminary findings suggest that CLIP’s approach to learning from diverse and naturally occurring data may contribute to improved robustness and generalization compared to traditional models trained on more narrowly defined, supervised datasets.
What problem is the paper trying to solve?
The paper addresses the problem of limited generality and adaptability in state-of-the-art computer vision systems, which are traditionally trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their usability and generalizability because specifying any new visual concept outside of these categories requires additional labeled data. Consequently, this approach is not scalable or flexible enough to accommodate the vast diversity of visual concepts encountered in real-world applications.
To tackle this issue, the paper introduces CLIP that learns visual models directly from natural language descriptions paired with images. This learning approach leverages the broader and more diverse supervision available in text, allowing the model to understand and classify a wide range of visual concepts without needing task-specific training data. By predicting which caption goes with which image from a large dataset of image-text pairs collected from the internet, CLIP learns transferable visual models that can perform a variety of computer vision tasks in a zero-shot or few-shot manner.
Madhu Korada
MRSD Student
My research interests include Computer Vision, EdgeAI algorithms, ADAS and robotics.